Table of Contents

A quick intro about NoSQL
A NoSQL or ‘Not Only SQL’ database is a non-relational and largely distributed database management system. It provides a mechanism for storage and retrieval of data that is modeled in means other than the tabular relations used in relational databases. NoSQL enables rapid, ad-hoc organization and analysis of extremely high-volume, disparate data types.
NoSQL databases are sometimes referred to as cloud databases, non-relational databases and Big Data databases. It was developed in response to the sheer volume of data being generated, stored and analyzed by modern users and their applications. Scalability, availability, and fault tolerance are the key factors which has made NoSQL databases the first alternative to relational database like SQL. Some of the distinguished implementations of NoSQL are Cassandra database (Facebook), BigTable (Google) and SimpleDB and Dynamo (Amazon).
Types of NoSQL Databases
- Document databases types – Lotus Notes, Apache CouchDB, and MongoDB. It pairs each key with a composite data structure known as a document. Documents can have different pairs of key-value , key-array, and the nested documents.
- Graph stores types – Neo4J and Hypergraph DB. Stores information about networks, such as social connections.
- Key-value stores types– Riak and Voldemort. It is the simplest NoSQL databases. Every single item is stored as Key-Value pair. Some of the key-value stores like Redis can contain each value with a type, say “integer”, which adds functionality.
- Column stores types – Cassandra and HBase data is stored in cells grouped in columns. It stores columns of data together, instead of rows. This Database have optimized queries for large datasets.
4 Factors which make NoSQL different from RDBMS (SQL)
Here are the factors to nosql vs sql
1. Tables or collections: The primary difference between relational and non-relational databases is the way data is stored. Relational data is tabular by nature – and hence stored in tables with rows and columns. Tables can be related to one another and cooperate in data storage, as well as easy retrieval.
E.g.: Data stored in RDBMS
|
Id |
User_Name |
User_Age |
User_Gender |
User_Country |
|
1 |
Abc |
34 |
Male |
India |
|
2 |
Xyz |
25 |
Female |
India |
Non-relational data, on the other hand, is just not meant to fit in tables of rows and columns, but rather grouped together in chunks. Data is stored in JSON format. Each document in a collection has a unique _id field, which is a 12-byte field that act as a primary key for the documents. Non-relational data is often stored as Collections, like in documents, key-value pairs or graphs.
Data stored in NoSQL
{
“_id”: ObjectId {“2fff324252fg2fff324252fg”},
”User_Age”:34,
”User_Gender”:”Male”,
”User_Country”:”India”
}
{
“_id”: ObjectId {“4hhh467854fg2jur32n652by”},
”User_Age”:25,
”User_Gender”:”Female”,
”User_Country”:”India”
2. No Schema or Fixed Data model: Data can be allowed to insert in a database without prior definition of a rigid database schema. Therefore the format or data model being inserted can be modified any time, without application disruption, thereby providing immense application and business flexibility.
On the contrary, relational databases require that schemas be defined before you can add data i.e. table structure, columns and datatypes are predefined. For example, you might want to store data about your customers such as phone numbers, first and last name, address, city and state – a SQL database needs to know what you are storing in advance. Here, even minor changes to the data model have to be carefully managed and may necessitate downtime or reduced service levels.
E.g.: Consider 2 different document in same collection but with different schema in NoSQL. This kind of flexibility is very complex to handle with RDBMS.
array(‘id’=> new MongoId{“4hhh467854fg2jur32n652by”},
‘name’=> ’xyz’,
‘age’=> new MongoInt32(31),
‘country’=> ’India’
)
array(‘id’=> new MongoId{“2fff324252fg2fff324252fg”},
‘name’=> ’abc’,
‘gender=> ’Female’,
‘email=> ’abc@gmail.com’
3. Structured / Unstructured Queries: Relational databases manipulate data through what’s called Structured Query Language (SQL). SQL is incredibly powerful for supporting database CRUD (Create, Read, Update, and Delete) operations using primary and foreign key relations.
On the contrary, Non-relational databases manipulate data in chunks (like documents) and use something called Unstructured Query Language (UnQL). There is no fixed schema and no joins.
E.g.: Suppose, in RDBMS we have 2 tables’ User and User_Information, having the following Primary Key (PK) and Foreign Key (FK)
Thus, In RDBMS each table has PK and User_Information table has User_Id has which act as FK. If we try to insert a row in second table, it would have dependency on values in first table. In case the corresponding User_Id is not available in first table, inserting a row in second table would throw an error.
While in NoSQL, following would be the structure:
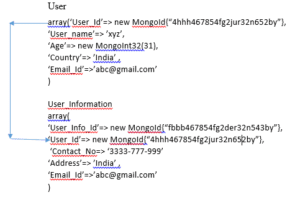
Here, if we insert any data in User_Information table which does not exist in User table NoSQL database will not throw any error.
4. Bigger Architecture /Data Handling Capability: The volumes of data that are being stored have increased massively and so the transaction rates. Today, the volumes of “big data” that can be handled by NoSQL systems, such as Hadoop that outstrips the features of biggest RDBMS.
In this blog I discussed about what NoSQL is and how it can handle huge volume of data. I will be discussing about “Challenges involved with NoSQL” in my next blog . Stay tuned!



